
Check out the source code on Github
Contents
Vision
In preparation for my Master's thesis, trying to better predict tornados by combining satellite images and Doppler radar, I decided to try a small project to grasp the combination of metadata for context with images. One of my professors offered up an idea for this, utilizing trail camera pictures of deer with the onboard sensor data. This data consists of the wind, the moon phase, temperature, time, and more, all things that could provide additional insight into deer behavior and predictions.
Goals
- Make a layered Convoluted Neural Network model for images and time series data
- See if Metadata improves model accuracy
- Try and beat the trail camera manufacturer's model
Data Collection
The images for this project came from a trail camera, which uploaded images to the cloud. Gathering images would consist of inspecting the web requests, finding the endpoint, and finding the authorization token. Easy enough. After this, images would have to be downloaded from the endpoint, in this case, s3.
At this point, I did come to the unfortunate realization that there were only about 3,500 images. This made the acquisition much easier but did not have great hopes for the model itself.
Moving on to tagging, I utilized a small Python Tkinter program to pull up the image and then put the labeled result in a JSON. Not as impressive as something like RoboFlow, but it got the job done and allowed me to get through the 3,500 images pretty fast.
Data Processing
Once images were imported, the metadata was cleaned up and dumped into a CSV along with the image location, which would be fed into the model. Additionally, the metadata would have to be regularized, and from suggestions of ChatGPT, formatted into standardes like cyclical and binary indicators. The images were then downsized to the usual 224x224, and the pixels were flattened.
I had originally planned also to remove duplicate images - which became an entire process of trying to reverse engineer a Python library that was originally written to be a command line tool (which I got working) but ended up not being needed since it removed too many images and reduced the training set substantially. Also technically the images were not duplicates since the metadata would separate them, but that was beside the point.
When processing the images, the small border at the bottom containing basic metadata was also stripped. It did occur to me that this strip was essentially feeding metadata into the model, rendering this technique a little useless, but the tornado data would not have this embedded so it still stood.
Training
With a mixed input of images and metadata, this model would be a little more complicated than things I had worked on before. My first idea was to simply train two models - and then combine them.
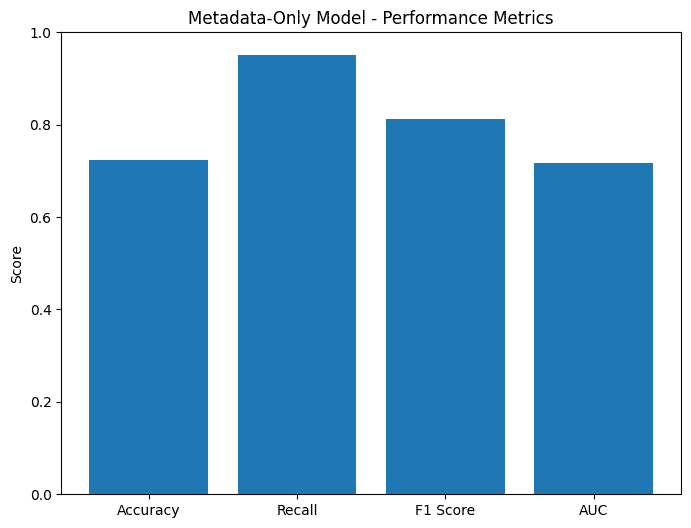
The metadata would consist of a dense neural network, with only one layer since the information is pretty light.
While the image model would be a convoluted neural network, with a couple more layers.
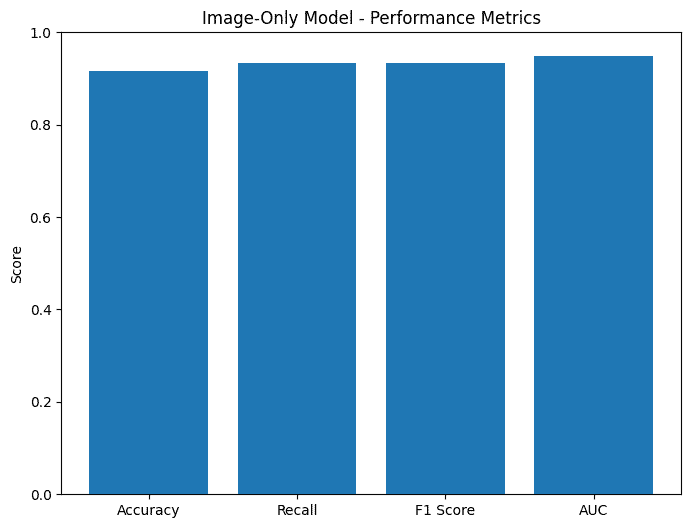
To optimize this model with the small dataset, the amount of layers was kept small and dropout was not trimmed too aggressively. Additionally, I tried other methods like Transfer learning from ResNet or ImageNet but this resulted in lower accuracy.
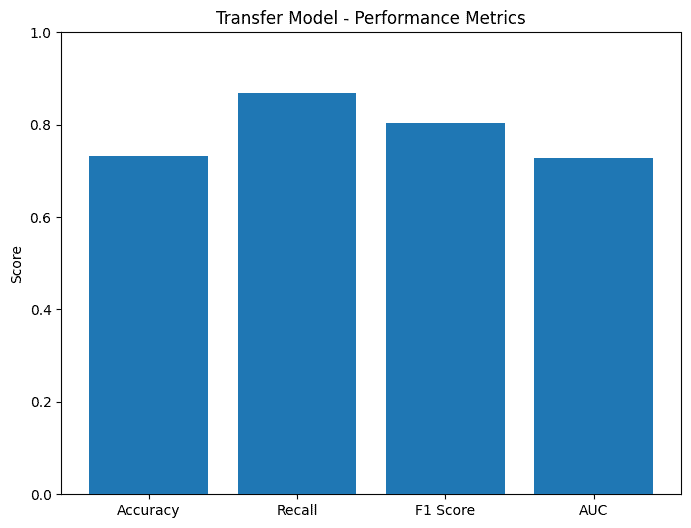
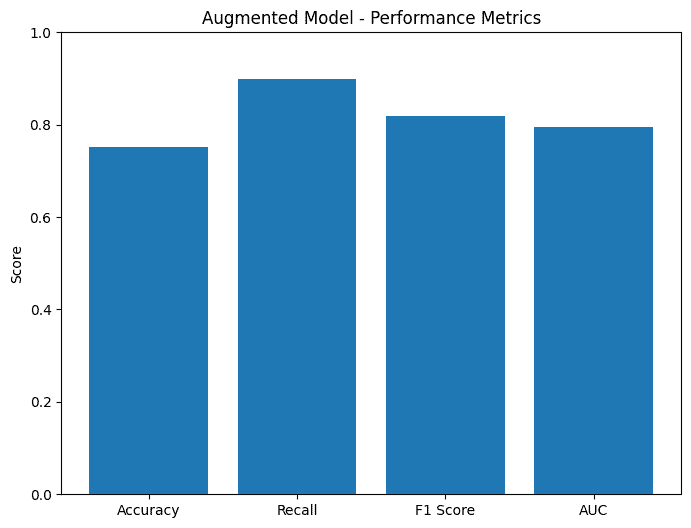
To expand the dataset, I also tried Augmentation, but that also lowered the accuracy.
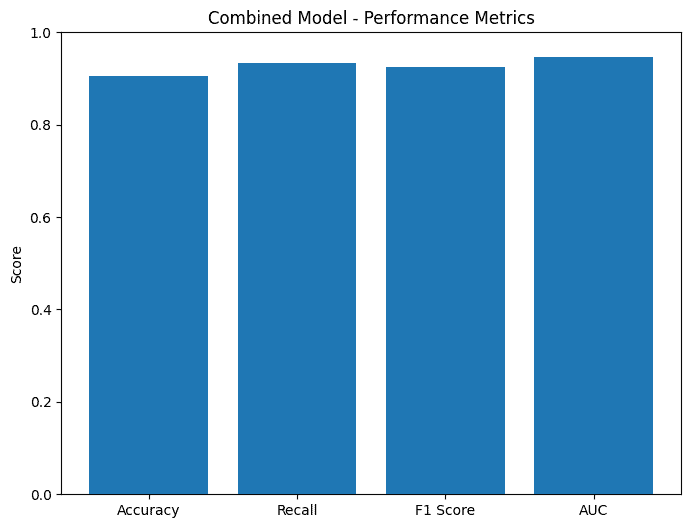
And finally, the combined result of the image and metadata model.
Results
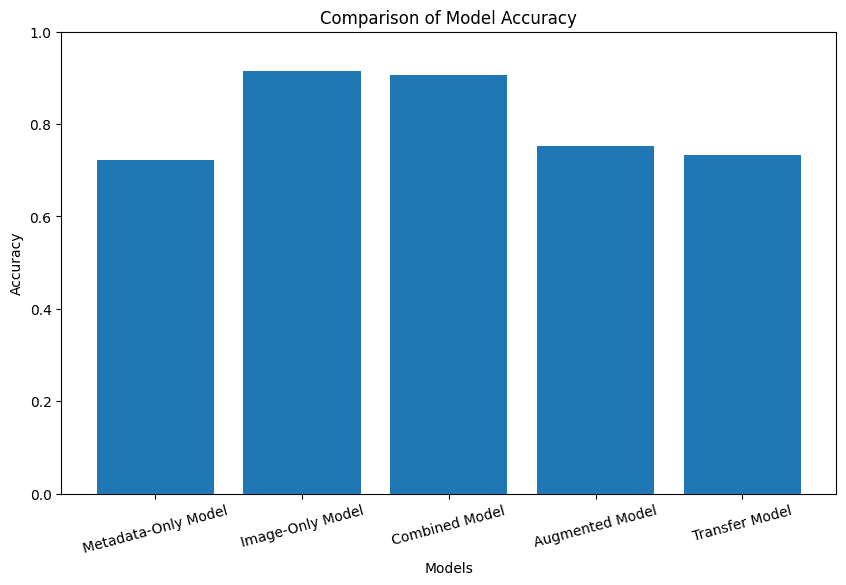
As a baseline, the original trail cam manufacturer's accuracy versus my manual tagging was about 92.24%. Unfortunately, none of my models came close to that - and unlike the manufacturer's model, they did not tag species or locations in the images. But this was to be expected as they most likely used some kind of YOLO model and trained on a lot more data - outside of the scope of this project.
The really unfortunate part was that the accuracy of the combined model, at about 90.61% was less than the image model, at 91.55%. Looking at the low accuracy of the metadata-only model at 72.3%, this is likely explained by inconsistent metadata with deer spottings. So maybe the idea wasn't the best...
Until you consider the performance. The evaluation time for the combined model was 0.798 seconds, compared to the image-only time of 2.058 seconds. Showing that the improvements of the metadata substituting might not only show in accuracy but show significantly in prediction time. Over half the amount of time required. That's impressive.
Looking at the accuracy graphs, the combined model does not do the worst either, in fact, it's pretty close to the best-performing image-only model.
And looking at the evaluation time graph, it also strays far away from the worst performing.
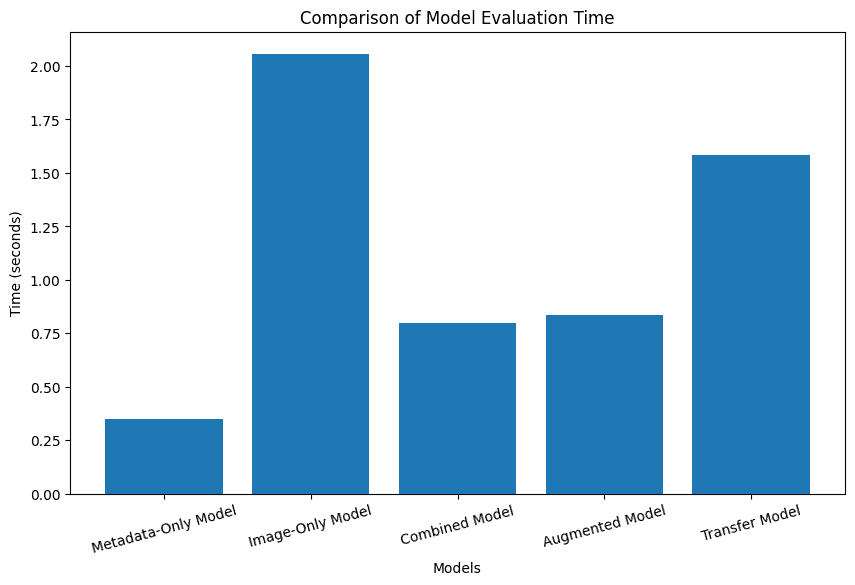
Overall, I would consider this a success. While the accuracy took a hit, it remained high at 90.61%, and seeing a noticeable performance increase over the image-only model is more impressive.
Discussion
Many of the limitations faced by this project were because of the small dataset. The model had to be kept small, as complex models did worse by just memorizing specific things. Dropout and overfitting prevention were not an option as they would just forget all important details. In general, the testing data was probably just similar to what the training data was on and it probably just memorized features anyway.
With a larger dataset, it would be interesting to return to this and try and gather more information about weather from other sources to make this a stronger metrics-aided image prediction model.
If this worked well, it could be combined with other cameras to have a higher degree of accuracy in predicting deer in trail cameras and suggest things like where to hunt based on confirmed deer movement.